
在网页 404 前将其备份的不同方法
不知为何,许多有态度有看法的文章也被划入「不合适」一类。有人说过,互联网是有记忆的,任何个人、组织都不能真正将其抹杀。而我们能做的,就是将这些记录保存好。

「不存在」的文章
一篇文章,特别是网上的文章,有可能由于某种原因无法在被阅读。可能是网站被屏蔽,可能是被平台下架,可能是作者手动删除。
这时候,有效地将网页备份好,不仅方便自己之后复习查看,也同时方便更多人继续感受作者原来的思想。这次就介绍几种将网页保存下来方法。
本地备份
直接将页面保存到本地应该是最直接的做法了,只要硬盘还在,你一直都能翻阅你保存好的内容。只不过这样方便不到他人就是了。
下载到本地
其实说到「保存」,应该马上联想到「下载」。
确实,直接将网页下载到本地是最方便快捷的方法之一了。桌面端直接 ctrl/command + s 即可。
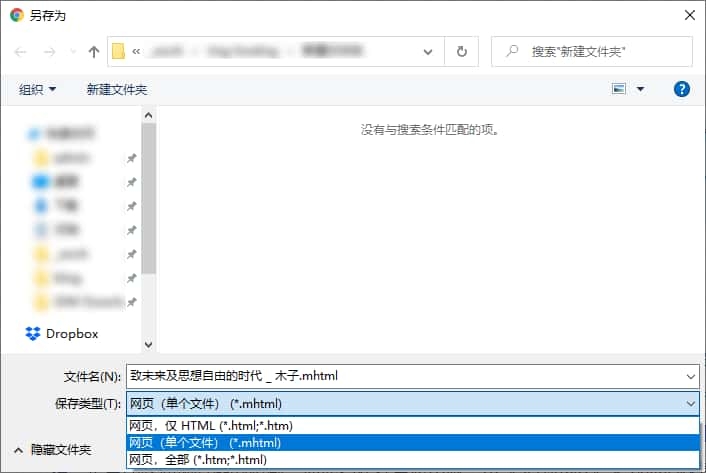
这里我们发现有三种保存方式。我们知道,一个网页,除了 HTML 文件本身,还会有 CSS 样式文件、JS 脚本文件、和使用相对路径调用的媒体资源等。这时候如果仅保存单个 HTML 很可能没法完整还原阅读体验,所以不建议使用第一种方式。而第二种和第三种都能较好地存档单个页面,区别在于第三种是将该 HTML 页面所需的资源单独下载到一个与 HTML 同级的资源文件夹内(在你没有移动的情况下),并将 HTML 中的资源调用替换为使用相对路径访问下载好的资源文件夹;而第二种 MHTML 称为聚合超文本文档,直接将所有资源封装到一个 MHTML 文件内,不再需要资源文件夹,分享的时候也只需要发送这一个 MHTML 页面,避免可能遇到的路径问题。
所以结论是,建议使用第二种方法保存网页。Android 手机的主流浏览器(如 Chrome)也可以使用「下载」方法保存网页。
注意 Android Chrome 默认保存为 HTML,需要在 chrome://flags 中将 #offline-pages-live-page-sharing 调为 Enable,这样才会默认保存为 MHTML。
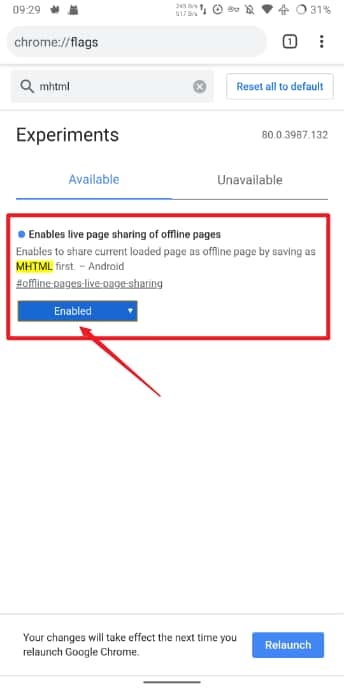
而 macOS/iOS 则是保存为 WebArchive 文件,和 MHTML 一样,这种文件格式也是将页面元素全部封装到一个文件内.
保存为 PDF
将网页「打印」为 PDF 也是一个十分方便的办法。你不用担心样式、资源问题,因为 PDF 就完完全全是你打开这个网页所看到的样子。
在电脑上,你可以使用 ctrl/command + p 打印当前页面,并在「目标打印机」选择保存为 PDF。
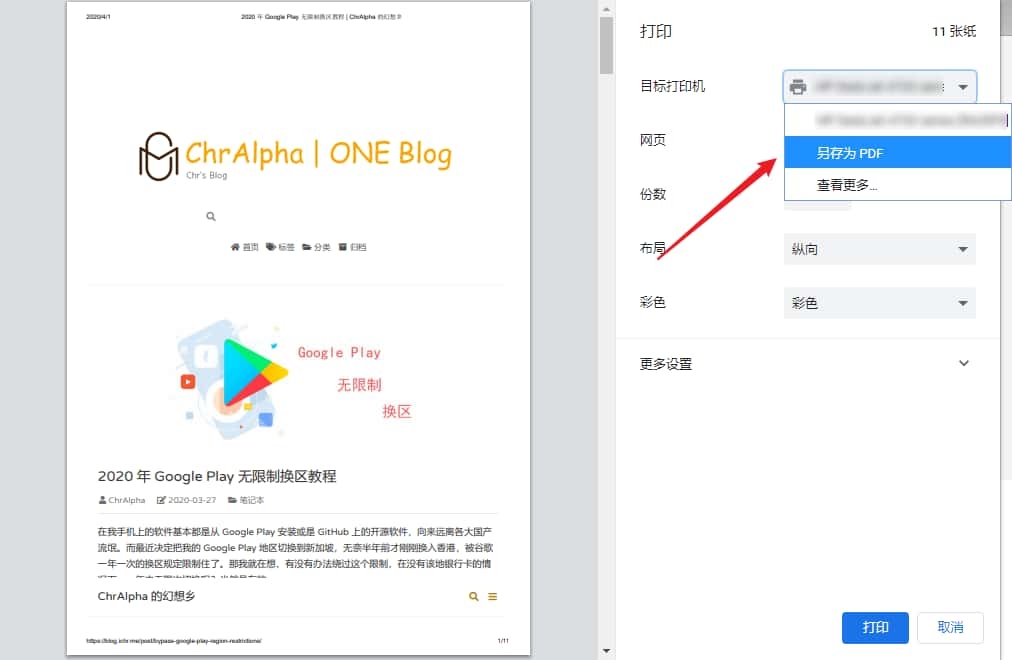
注意如果你部署了懒加载,记得一定要先让所有懒加载先完成,不然 PDF 里可能都是占位图,到时候就哭笑不得了。如果有类似我博客的导航栏,可能会跑到最下方,不过不影响文章主体的阅读。
手机端稍微麻烦一点。如果你使用 Chrome,默认是没有打印选项的,而我当初刷入的是 OpenGApps 的 nano 包,没有预装 Google Cloud Print,需要在 Google Play 中手动安装,这样在分享页面才会出现打印选项。如果你使用 Firefox,据说可以有保存为 PDF 的选项,这就方便很多了。
PDF 的优点是没有格式问题,保存下来就是你当初打开页面的样子,全平台都能很好的兼容。但缺点是没有响应式设计,在桌面端上保存好的 PDF 发送到移动端查看体验就很一般了。
以上两种就是比较常用的本地备份方式,至于长截图之类的操作就不单独介绍了。当然你也可以直接将页面复制粘贴到 typora,typora 会自动识别 HTML 并转为 Markdown 格式,之后就可以选择保存或导出为 PDF(typora 自带)。
在线备份
如果本地保存是一个人独享,那么在线备份就能很方便地分享,让更多人了解作者原本的思想。但相较于本地保存,在云端备份更容易受到不可控因素影响,大家自行取舍吧。
云笔记
许多云笔记应用,像是 Evernote/OneNote/Notion,都有网页剪藏功能,体验也都不错。
桌面端使用浏览器插件,移动端巧用分享功能,都能实现。
但我平时更倾向于书面笔记,对于云笔记应用使用较少,就不放详细步骤了。
Webpage Archive
其实说到在线备份,首先想到的就是 Webpage Archive 。
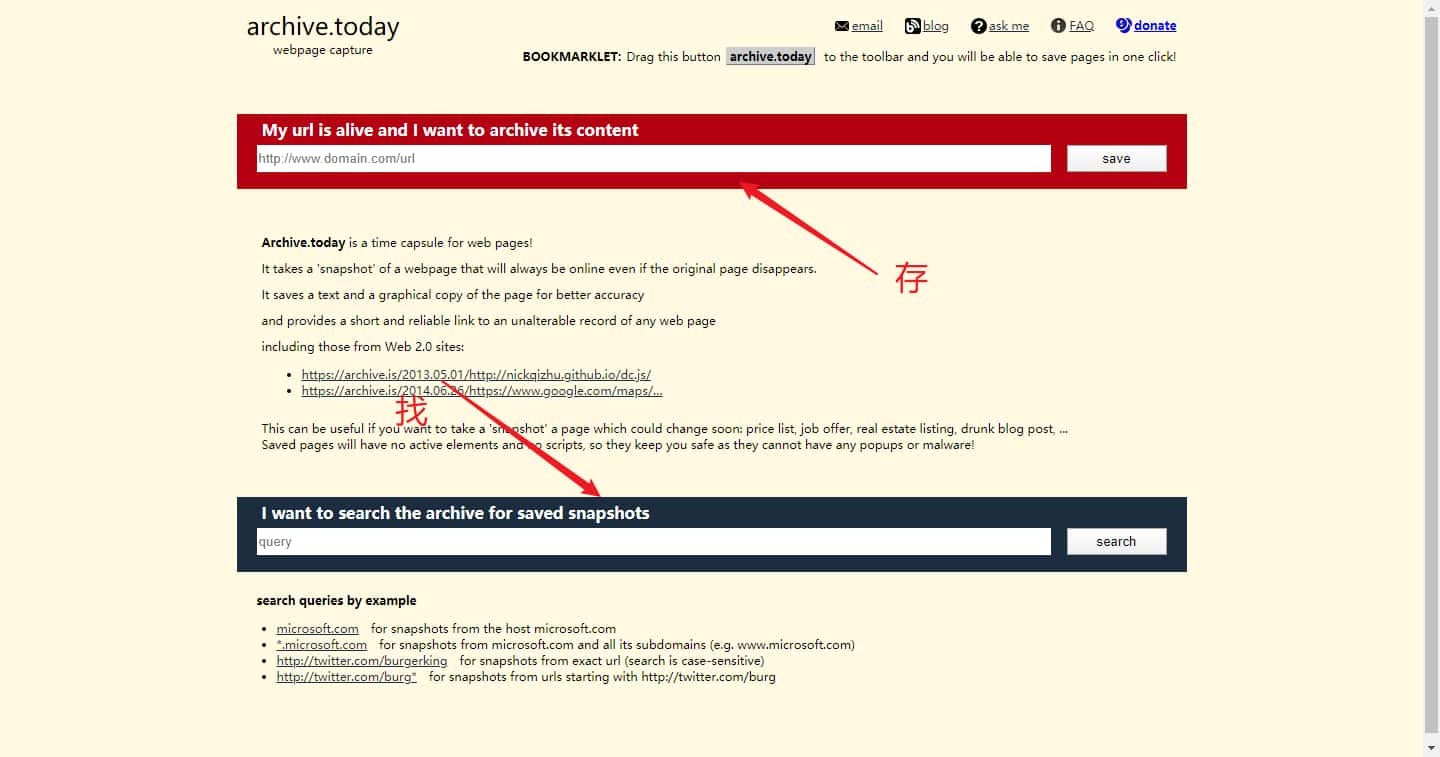
使用也非常简单。当你认为一篇文章可能比较敏感,就直接把 URL 粘贴到上面的输入框内并点击 save ,它就会帮你保存好当前这个版本。
而如果该页面已经「不存在」了,也可以尝试在下方的搜索框尝试搜索该网页,说不定别人已经随手保存好了。
Wayback Machine
和 Webpage Archive 一样,Wayback Machine 也是一款在线网页备份工具。
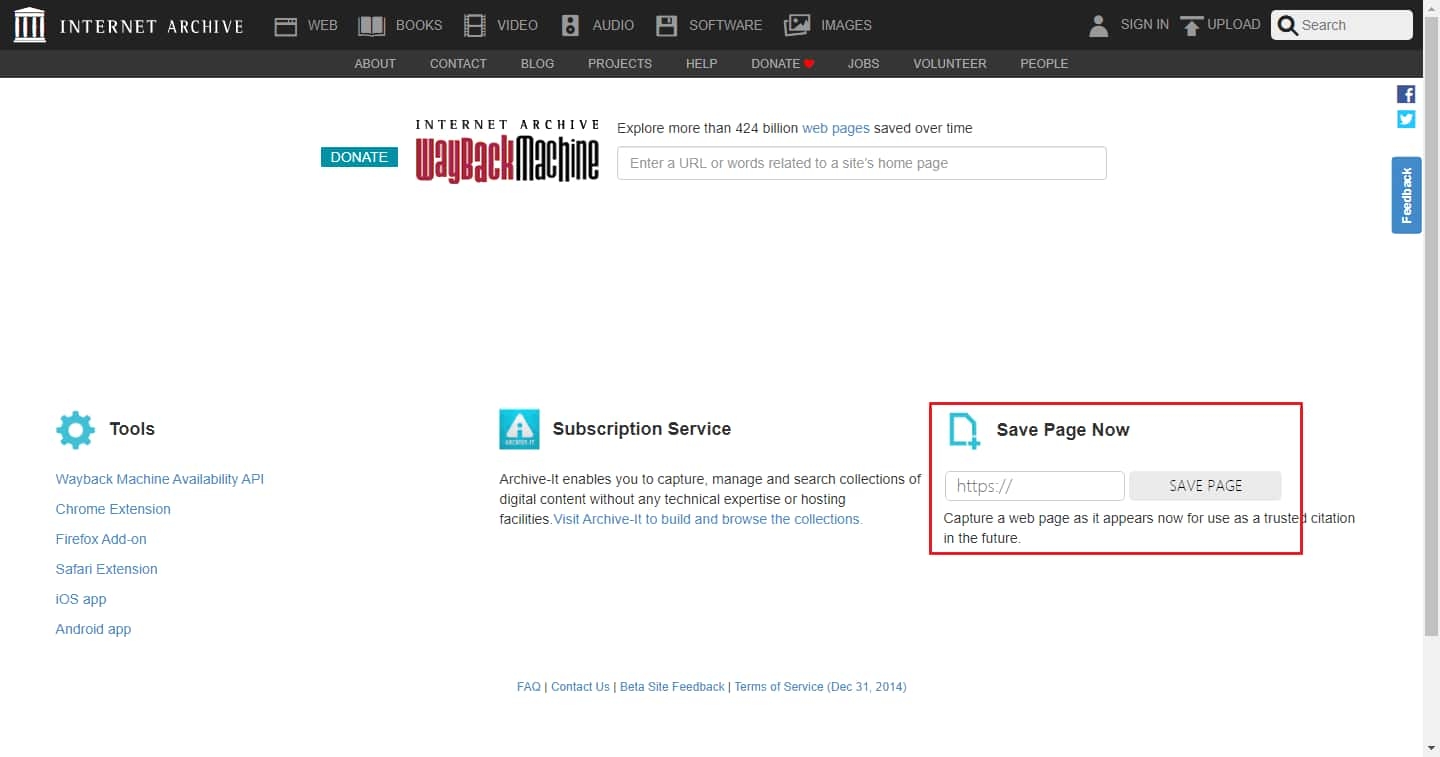
你可以在右下方输入框内手动保存页面,也可以使用搜索功能手动索引检查是否有人已经备份了。Wayback Machine 目前已经有 4200 多亿个页面存档,体量可以说是很庞大了。
而与 Webpage Archive 不同的是,据说 Wayback Machine 会根据谷歌快照等数据自动备份网站。不过这样至少需要网站有一定名气,且没有屏蔽爬虫,有被搜索引擎收录。像是微信公众号这种严重流量封闭的平台就不适用了。
浏览器插件
这里单独推荐一个 Chrome 浏览器插件——Archiveror ,它可以帮你快速备份网页到上面介绍过的几家在线备份服务中,或者单纯保存为 MHTML 到本地,你只需要右键该网页,就可以看到选项。
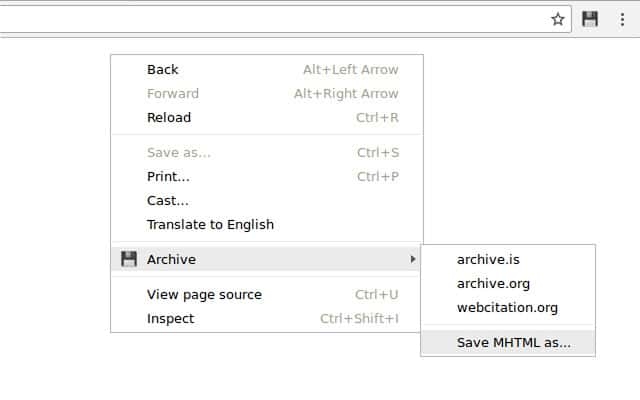
当然,这样一来该插件就可以访问你的浏览数据了。如果你不放心,那还是手动去备份吧。
后
看到有些优秀的文章被下架,不论原因为何,都应感到是可惜的。确实,在这个环境下,我们能做的只有真实地记录,或者让这些痕迹更加深刻,让其有迹可循。
其实说到抗封锁,第一想到的还是去中心化网络,比如区块链、BitTorrent、DHT 网络等等。但暂时还没有看到令我兴奋的解决方案,也欢迎大家讨论。
