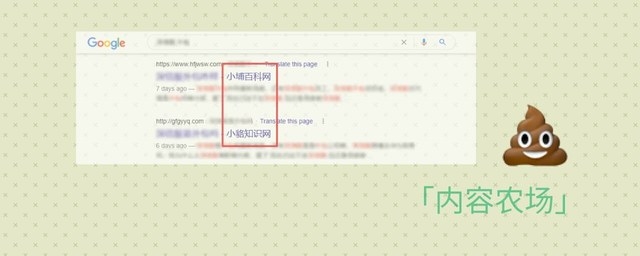
「内容农场」属实在玷污 Google 搜索结果
「内容农场」包括且不限于各类采集站、StackOverflow 机翻站、爬取各大网站的展示站。这些「农场」不仅不愿自己耕种作物,还窃取他人果实。再由于窃取的手段十分粗糙,要么借助机器大规模作业要么请素质一般的某生物简单摘抄拼接,最终展现内容的质量往往不敢恭维,甚至内容都不堪入目。
除了给始作俑者带来不干净但可观的收益外,「内容农场」也就只能给希望在互联网上汲取养分的初学者猛地喂一坨 shit 罢了。
前言
准备在 Google 上搜索关于 Windows 11 正式版推出后的一些信息,结果最上面却是一个奇怪的网站。这个网站力压知乎、cnBeta、Bilibili、IT 之家、网易号等老牌、流量大、更新频繁、SEO 权重绝不会低的网站。
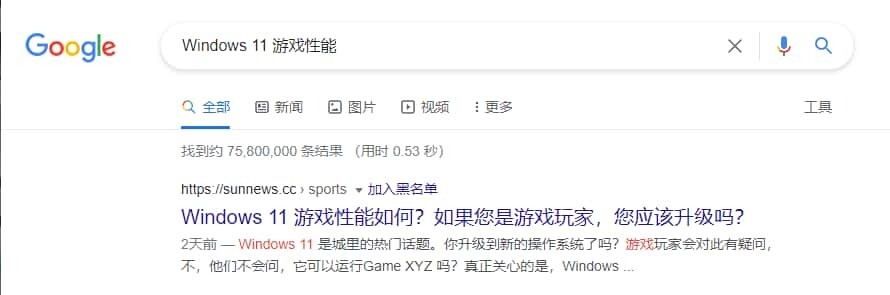
点进去,排版就看傻眼了。整个版面只有不到 20% 在显示正文内容,往下 7 页都是指向站内的链接,还全都是当天发布的。点开首页、各个分类下面,发现他们更是勤勉,每天更新百余篇文章……当然不是他们写的,有的文章末尾标注了公众号(估计是原文就标注了),可更多压根找不到来源标注。
无独有偶,曾经臭名昭著的「兰州养生网」,再到最近简直疯狂的「小XXX网」。V2EX 论坛上就在这周冒出许多吐槽的帖子,据说收集到的分身域名有多达 2500 个,后续又更新到 5 千、6 千个,丧心病狂。
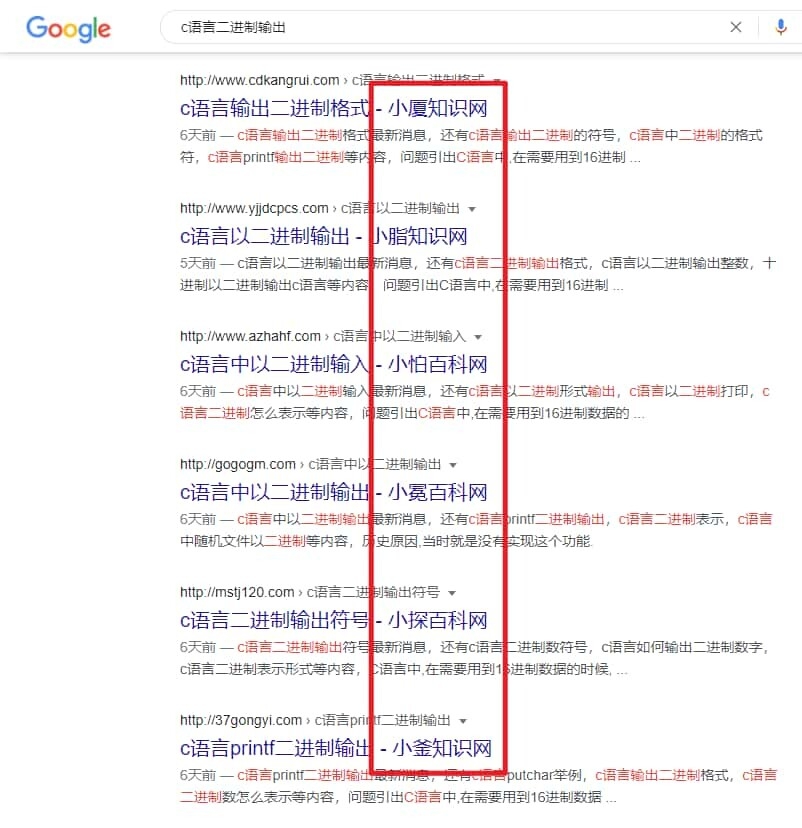
它叫「内容农场」
这种充斥着劣质信息的采集站,有个专门的名字——内容农场,Wikipedia 就有一个词条专门介绍它。
「内容农场」是指为了牟取广告费等商业利益或出于控制舆论、带风向等特殊目的,快速生产大量网络文章来吸引流量的网站。此类网站通常找不到作者、管理者、网站负责人,也不会主动管理产出的内容,对侵权或错误内容投诉的处理也很消极。其产出内容多半都是缺乏原创性且真实性无法保证的内容,且有极高比例是盗用、盗译自他人的原创图文,或由非专业写手胡乱拼凑网络文章而来,因而多半缺乏可靠来源、质量低劣、不具参考价值、传播误导讯息,也经常掺杂大量广告或恶意程序。
这些网站偏偏抓住搜索引擎无法自行衡量内容价值,单用及其频繁的更新速度来套取搜索引擎的青睐并给到一个比较高的权重,甚至不用太关注 SEO,只要更新频繁 Google 自己就会主动会来爬取。由于真人一眼就能看出这是垃圾桶,所以内容农场也不会自讨没趣通过社交媒体转播,而单单扣住搜索引擎获取流量并走到极致。而且这种行为是有利可图的,身处流量时代,流量变现的门槛实在不高,接入广告平台就可以躺着收钱了。
你贪图利益与我无关,但妨碍到我正常搜素那可不能坐视不管。本来有网友热心撰写文章,却被垃圾文章挤占原本该属于前者的搜索结果高位。真正创造价值的人得不到应有的报酬,倒是垃圾的制造者赚的盆满钵满。
如果你搜索内容所在的领域恰有大量爱好者、从业者自发聚集并创建了领域内的论坛、博客等,被采集的概率也会更大。比如程序员社区,各种机翻 Stackoverflow、爬 GitHub 的 gitMemory 等网站层出不穷,许多「面向 Google 编程」的 Coder 没有太多精力甄别便为其送上流量。某些互联网大厂还带头干过这种事。
其实不仅中文搜索结果被下毒,其它语言的搜索结果也会时不时冒出内容农场来。但是开放精神不同程度缺失的中文互联网,各大公司迫切地将流量盘在一个个信息孤岛内。比如说公众号,不仅禁止搜索引擎爬取、不提供 RSS 输出、不允许文章聚合工具整理。想要发现更多优秀的公众号?请在社群中随缘相遇吧。对全局检索、发现新内容极不友好。
而事实上,公众号还是有不少不错的内容的,既然搜索引擎直接检索是检索不到的,那用点别的手段骗过公众号拿到内容,然后再整理放到一个网站开放给谷歌检索,补齐公众号文章本应从搜索引擎进来的这部分流量,然后借这些流量变现。
这类想法甚至还有点自然。所以,从某种程度上来说,国内互联网生态封闭的特点倒是在给内容农场筑势。
除了往你的搜索结果中倾倒垃圾内容,这种网站有时甚至不满足于你贡献的点击流量,还在页面中植入恶意代码……它们百害而无一利。
面对内容农场,可以做什么
放着内容农场不管,一直让他恶心自己不成?比起等待 Google 的动作,不如自己动手处理来得实在。
对于搜索者
等待搜索引擎清理站点过于漫长,但我们可以在搜索显示结果前自行过滤结果。目前像浏览器插件 uBlacklist、Personal Blocklist 等、油猴脚本 Google Hit Hider by Domain 等都能胜任过滤器的职责。
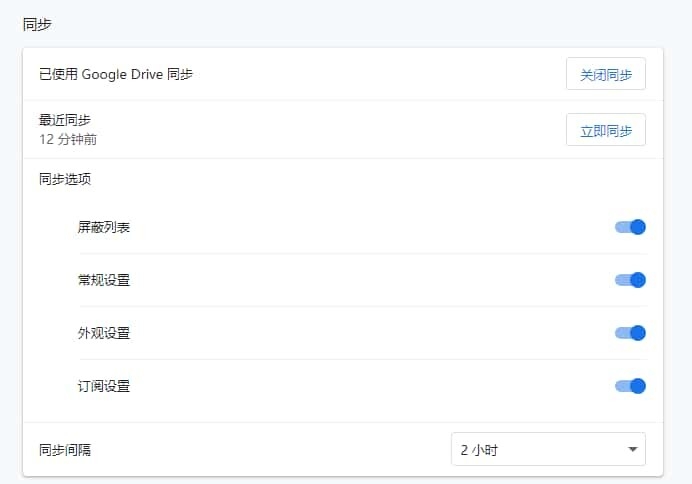
几个过滤器中较为推荐 uBlacklist——同时支持规则订阅和标题匹配,还能借助 Google Drive 或 Dropbox 在多设备之间同步配置。你可以在以下渠道获取 uBlacklist:Chrome Web Store、Firefox Add-ons、Mac App Store。
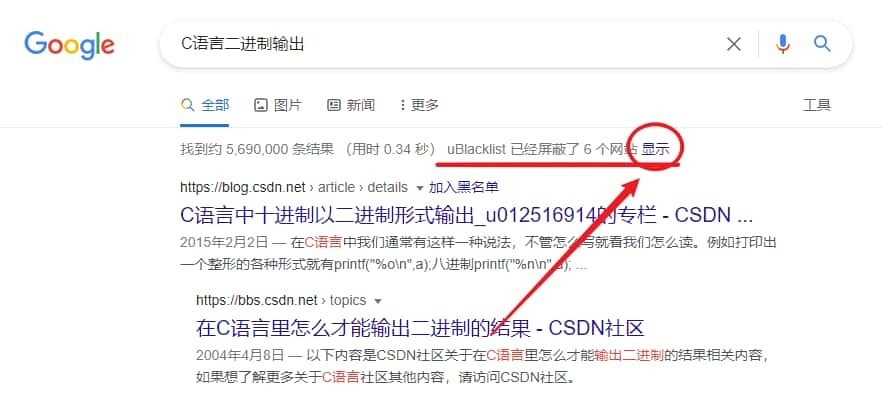
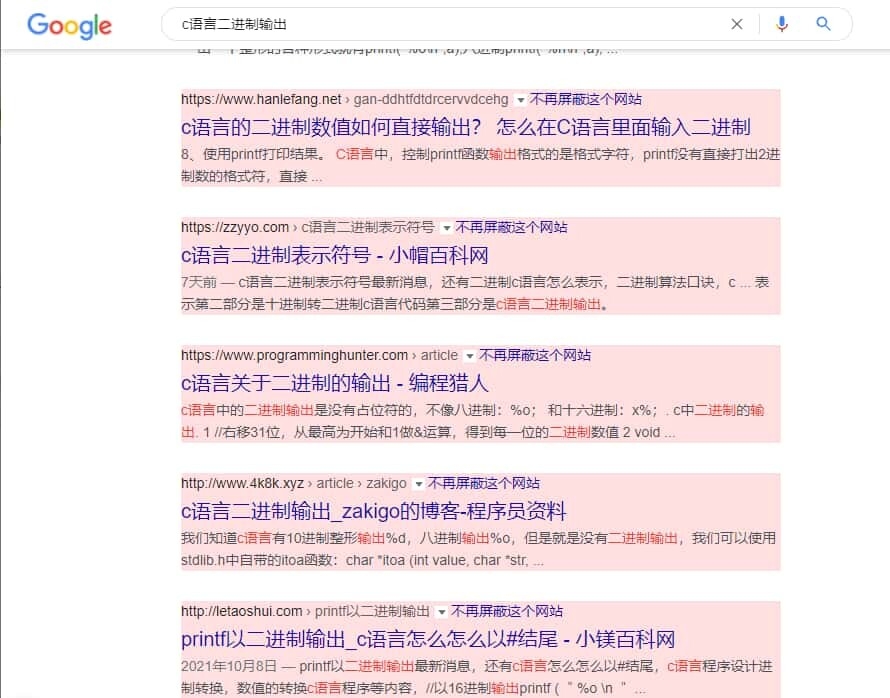
插件默认支持处理 Google 中的搜索结果,你也可以赋予插件「读取和修改网页数据」权限后也支持修改必应、DuckDuckGo、Startpage 等搜索引擎。安装后就可以通过搜索结果后面的「加入黑名单」让这个域名下的内容不再出现在你的 Google 搜索结果里。
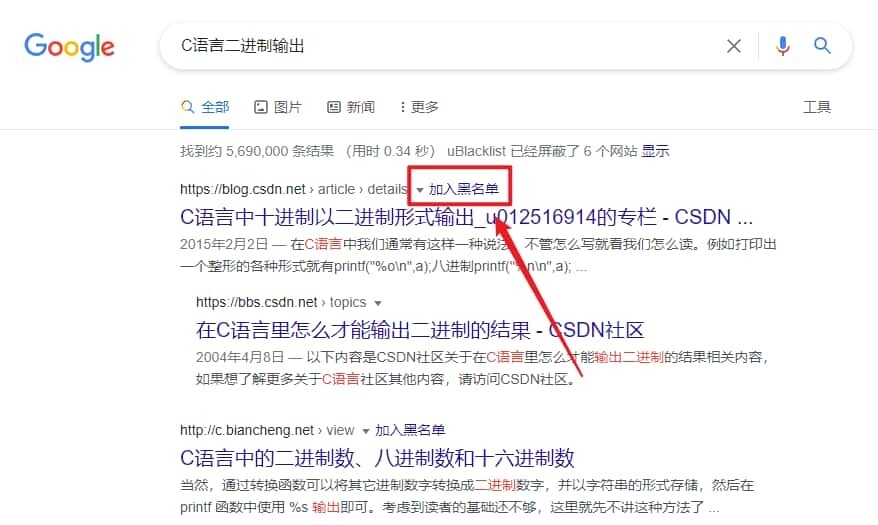
同时,你也可以点击上面的「显示」来暂时显示已经屏蔽的域名下的条目,这些条目还会被显眼的颜色标注。
加入你有多态设备,也无需在每台设备中配置一次,可以在插件选项中设置同步选项。
对于像上面「小XXX网」有数千个分身域名的内容农场来说,指望用户一个个添加显然是不太现实的。众人拾柴火焰高,我们可以订阅社区维护的规则列表来更方便快捷地过滤掉很多域名。这份订阅按需求更新即可,并不需要太频繁。
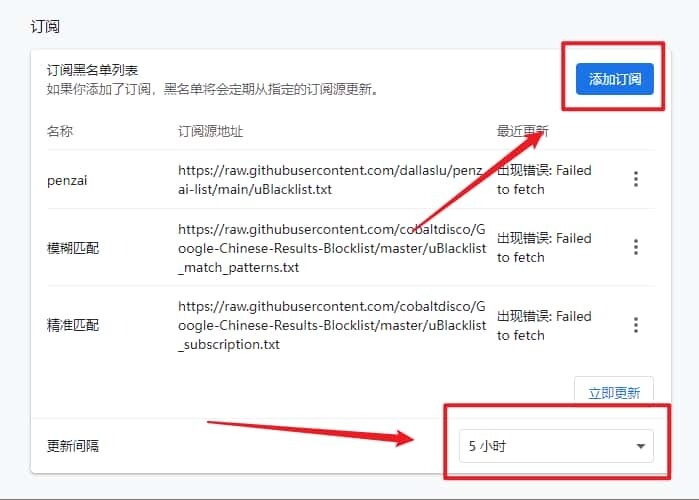
关于规则订阅,我暂且只推荐几个,欢迎各位路过大佬评论给出更多。
- 中文搜索结果黑名单:一个维护了 4 年的规则,截止本文写作时 GitHub 已拥有 4.4k Star。
- 「小 X 知识百科网」清单:针对
g.penzai.com及其数千个分身域名的规则,可以用于处理最近突然爆发的「小XXX网」。 - 针对 机翻 Stack Overflow 和 GitHub 采集站的规则。
这种方案的缺点也很明显,除了 iOS 15 的 Safari 目前已经支持插件,其它移动端主流浏览器几乎都不支持插件,在移动设备中搜索可能还是只能忍受劣质内容充斥首页。哦不,Firefox、Kiwi Browser 等浏览器支持安装扩展,如果你舍得抛弃 Chrome 及其背后的谷歌生态,拥抱可能割裂的移动端浏览器体验,倒也不失为一种选择。
对于创作者
首先感谢你们的存在,正因你们才使得中文互联网不至于那么槽,你们不可谓不是无尽黑夜中的点点星光。
为了不让你们的辛苦成果被他人窃取,自然是要采取一些手段防备的。
robots.txt 肯定是无效的,它更像一种君子协议,知名的爬虫一般会遵守。但这些没底线的抄袭者做的爬虫还是别指望了。也可以对 IP 访问设置阈值,若 IP 频繁访问就拉清单。但其实也挺好绕过的,毕竟 IP 不值钱。
这种时候非专业人士最好还是借助互联网公司提供的方案,自己估计折腾不出什么。假如你的域名托管在 Cloudflare,可以通过 Firewall 基于 IP、User Agent 判断是否为品行端正的爬虫并由此决定是否放行。不妨打开「Bot Fight Mode」,至于会不会影响搜索引擎收录,Cloudflare 对此的解释是「不会影响符合规范的爬虫」,但这个规范为何没有很明确地指明,也只举例 Google 一个。所以请自行权衡,开启与否取决于你是否非常在意各个搜索引擎、各种榜单的收录了。

还可以尝试常驻 5 秒盾、hCaptcha 等,恶意爬虫倒是能比较好地挡住了,只不过会一定程度上影响真人读者体验。
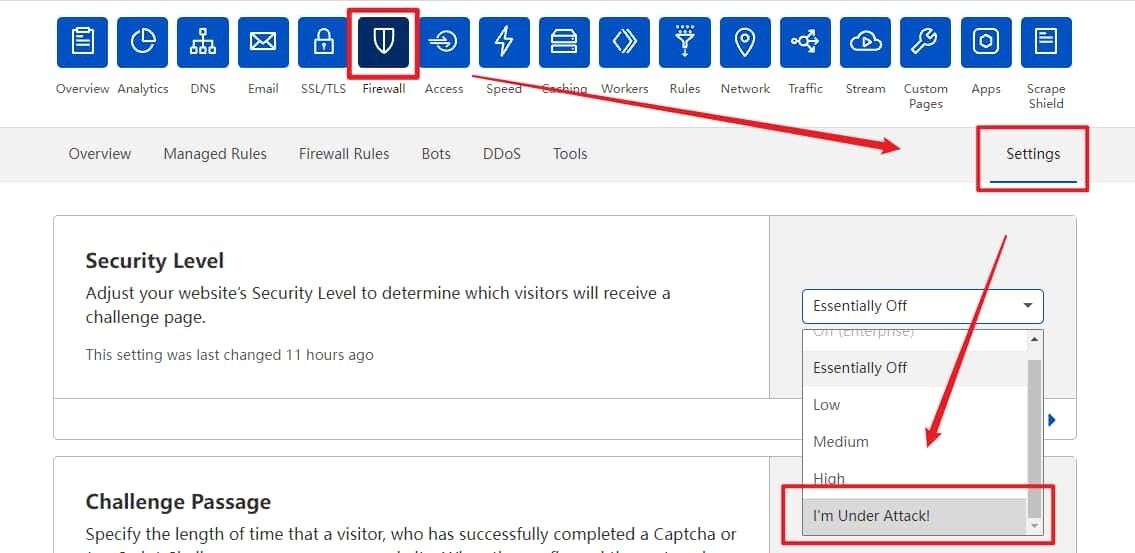
我并非此方面专业,自然说不出什么有价值的内容,此部分权当抛砖引玉,欢迎各位补充。
对于所有人
上面介绍内容农场的时候提到,假如人工介入,这种网站是很容易被 kill 的。所以,如果有空,不妨动动手在 Google 举报网络垃圾。尽管有点杯水车薪的味道,但总是添上一砖一瓦了的。
然而,做内容农场的人自然明白这一点。所以他们往往消极处理投诉,而更多的直接转战新域名。总之,把能做的先做了吧。
后记
通过备案查到 广东领讯网络科技有限公司,当然了,毕竟很少有非中文中主题运营中文内容农场的。天下内容农场共一石,中文独占八斗。
有人说,要养成使用英文搜索的习惯。诚然,编程上遇到问题我确实也更倾向于使用英文搜索,那很大程度上也是被 CSDN、阿里云社区、腾讯云社区逼的。而如今,随便搜个饮食、医疗相关的词条都有许多内容农场「从善如登,从恶如崩」般冒出。受限于地方差异,中文下对饮食的理解、描述很难被其它语言中的替代——下位替代都称不上。难道这方面的内容也要养成使用英文搜索的习惯?「开水白菜」怎么用英文说?
每次中文环境下出了问题,总是自然而然地切换到别的语言。我不知道这算不算一种背叛,但或多或少算得上逃避。从一开始互联网上完全没有中文内容,竭尽一代人努力后让中文成为互联网上第二多内容的载体,而如今却又不得不纷纷逃离。兴衰更迭,不禁唏嘘。
(简体)中文搜索会好起来吗?
不知道,但希望如此。
